
A while back I wrote a blog post about a packet filtering subcommand I implemented into GopherCAP. I recently had to clean up a 4 terabyte PCAP set that was known to have duplicate packets. This post describes a cool feature I added into GopherCap to deal with this problem.
How does packet duplication happen?
Duplicate packets in network capture are a pretty typical sight. The only way to truly avoid them is to buy a very expensive packet broker that handles this in hardware. Packet duplication can happen in many ways. We currently implemented Layer 2 (L2) deduplication but it is important to also understand how it can happen on higher levels.
- TCP retransmission - A TCP connection might simply require a *retransmission* when the original packet never arrived. Networking issues could have caused a drop or timeout before arrival but packet mirroring might have happened before it was dropped on the real network. These retransmitted packets are essentially duplicates.
- Routing loops - Routing issues can also cause duplicate packets. Loops in the routing table could cause the same packet to be shuffled between routers. Depending on the capture setup, that packet could be mirrored several times.
- Layer 2 loops - Loops can also happen on Layer 2. In other words, switches can bounce packets between each other before loop detection kicks in. If all of those switches are configured to mirror data, the result would be the same packet in the PCAP file for every loop iteration.
- Duplicate traffic sources - However, packet duplication can happen without any networking issue at all if packets are mirrored from every network switch and session spans over multiple capture points. For example, let’s assume that your organization is monitoring traffic from internal workstations segments and also from DMZ, or the segment that hosts public web services. A user in one of the internal segments accesses a web service hosted in DMZ. Packet would traverse the internal switch that would mirror it to capture. It would then reach the Layer 3 (L3) router or firewall which would forward it to the switch connected to the web server. Second switch would then also mirror the same packet. From a reassembly point of view, the second packet would be redundant.
Now, let’s assume that networking topology is more complex than the 2 switch scenario that was just described. Internal and DMZ segments might be separated by many intermediate L3 links that could also mirror the same traffic. Every mirrored intermediate link could add an additional packet. Web servers could be virtualized and those virtual links could also be configured to mirror traffic. The only way to truly avoid this is to purchase a packet broker that can do hardware deduplication. Not every environment has this.
The environment that originally motivated this work used a GRE tunnel to mirror packets from virtualized sandboxes. Hence, no hardware packet broker was present and the resulting PCAPs were known to suffer from packet duplication as described before.
Problems with duplicate packets
Presenting duplicate packets as input to any system – such as Suricata – will result in higher processing cost for each reassembled session. Suricata might also alert on each duplicate packet, which can cause confusion in security operations. The biggest problem, however, is simply the cost of storage. Our use-case involved large PCAP files where we knew that a significant amount of it was useless. We also wanted to be able to reparse those capture files in the future with newer versions of Suricata, using alternative rulesets, etc. Fully re-parsing this amount of data can result in significant downtime for security researchers. Remember the legendary xkcd comic strip.
Implementing Layer 2 packet deduplication
Before proceeding, please note that our goal was simply to reduce the number of packets in a PCAP that had already been captured. The software outlined below can never compete with hardware-based solutions, and it is not meant to scale on live networks. In other words, it’s meant for use in an offline lab.
The packet deduplication logic I implemented was directly inspired by similar functionality that was built into Arkime Full Packet Capture some time ago. It simply hashes the IP header together with TCP or UDP headers.
To do this, we use the gopacket Layers API to iterate through packet layers. Byte values of those layers are then added to the hasher. We skip over TTL and packet checksum bytes for IPv4 packets and Hop value for IPv6 packets. Remember, we’re observing a packet traversing multiple L2 switches. Packet TTL (time to live) and hop count would be decremented on each L3 hop. This method also fully ignores the MAC addresses on the Ethernet layer, as each switch the packet traverses would update those to local values. That’s how layer 2 switching works, as the switch needs to know where to send the response without knowing the public IP address. As a result, packet checksum also changes on each hop as we’re observing packet values with slight byte variations.
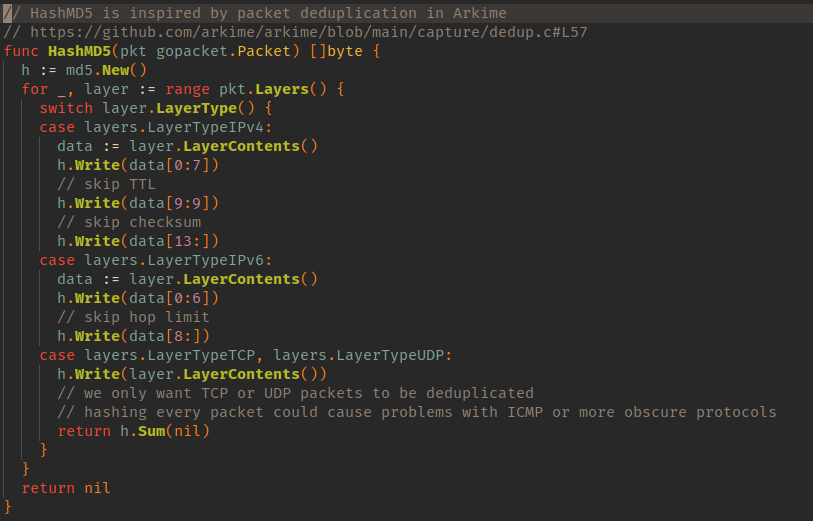
Computer memory is not infinite and MD5 hashing is known to suffer from collisions. It was simply chosen over more robust methods as it’s much faster. Strong cryptographic hashing methods are not designed for speed. They are designed to provide strong guarantees for uniqueness. Non cryptographic hashing functions such as Murmur3 or FNV could also be used, but those have very high collision rates and are mainly useful for probabilistic algorithms. So, we chose MD5 – it is a good middle ground between the two.
We implemented a circular array of buckets in order to track hashes that we’ve already observed. We store the timestamp of the latest bucket along with maximum duration and circular buffer size.
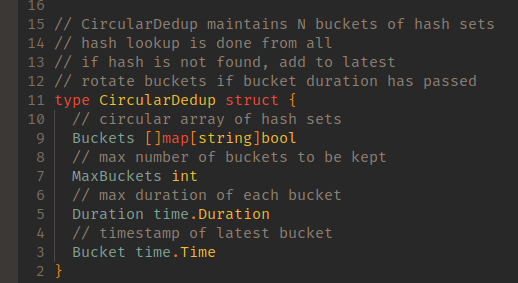
Whenever we see a new packet, we hash it using the function shown above. A missing hash value means we don’t support this packet type yet. That means we ignore ICMP, obscure transport layer protocols like SCTP, routing protocols, etc. We don’t want to accidentally drop more than we have to. We then use textual representation of the hash sum as a lookup key, and we try to find it in all existing buckets.

If the packet was not found, we add it into the latest bucket.

Finally, if elapsed time from latest bucket start exceeds threshold, we add a new empty bucket and update the latest bucket timestamp to be truncated into a multiple of the duration. We drop the oldest bucket if the new bucket count exceeds maximum.

Performance
GopherCAP currently sets up a deduplicator for each worker task and creates 3 buckets with 2-second bucket durations. Therefore, GopherCAP maintains a 6-second buffer that was more than sufficient for the exercise dataset we needed to deduplicate. When reading a compressed PCAP file at 100 megabytes per second, at 180000 packets per second, we observed memory usage per worker at 256 megabytes. Each task was tracking between 300000 and 750000 unique packet hashes.
Our dataset had packets that traversed at least 2 mirrored segments. We observed an on average 50 percent drop rate with deduplication enabled per filtering task. This was in line with what we expected. Interestingly, deduplication actually made packet filtering tasks slightly faster at this drop rate. Without deduplication, we would observe a worker reading a PCAP off SSD at 150000 packets per second and reading data at 90 megabytes per second. With deduplication enabled and drop rate at 45 per cent, the same worker would read packets at 180000 packets per second and 107 megabytes per second. This is expected, as we skip actual packet filtering. Nor do we need to write that packet into a new file.

When combined with additional subnet filtering as described in a prior blog post, we were able to reduce the 4 terabyte dataset to only 1.2 terabytes. That’s much more manageable, easier to store, and faster to transfer to other systems for replay.
Usage
Packet deduplication was merged into version 0.3.1 of GopherCap which can be found here >>. Advanced users are still encouraged to build the latest master, however, as GopherCAP is intended to be a tool for experimentation. Simply use the new –dedup flag and point the filtering subcommand to input and output directories. See example below.
This version also added some quality-of-life improvements to the filtering subcommand. For example, filter YAML is no longer mandatory. Thus, it can be used to only decapsulate and deduplicate packets without actually applying filtering.
In conclusion
Packet duplication is a problem that can arise from all kinds of networking conditions and without anything going wrong. The logic outlined in this post is intended as a lab solution and does not aim to be a production-class solution. For that you should seek a dedicated hardware appliance – such as a packet broker – that deals with traffic before it is captured and the PCAP is created. However, because we know this can be a problem in a software-only environment, we implemented simple deduplication that works by hashing packet IP and TCP/UDP headers.
The resulting PCAP is a much smaller research dataset. And as a side bonus, it actually makes packet filtering a little bit faster.
Try GopherCAP for yourself
GopherCap is available now on the official Stamus Networks GitHub page. We encourage you to give it a try, share your feedback, and even help improve it if you wish. Whereas this post focuses mainly on the initial replay feature, our vision is to - over time - add more PCAP manipulation features and build a unique multitool for the mad scientists in the threat hunting community.
For more GopherCap news and discussion, join the GopherCap Discord Community from Stamus Networks.



