
Historically, we have used tcpreplay with predetermined PPS options for replaying PCAP files. It is a part of our development, QA and threat hunting pipeline. But recently we encountered severe limitations when working with large and out-of-sync datasets. That led us to develop a better open source alternative - GopherCAP.
Background
Stamus Networks develops Stamus Security Platform and open-source SELKS, network security platforms. We specialize in network detection and response solutions which include signature ruleset management, network threat hunting, advanced threat intelligence and data analytics. All leveraging the Suricata network IDS/IPS/NSM engine.
Our development and QA pipeline is therefore data-driven, which is just a fancy way of saying we rely on replaying PCAPs over and over again.
Historically, we have used tcpreplay with predetermined PPS options. When setting up replay for a particular bigger-than-average PCAP set, we initially tried the typical bash rocket approach. Just read PCAP metadata using capinfos, extract average packet rate and then replay the file at that extracted average rate. Not ideal for developing algorithmic threat detection, but the result should be close enough, right?
avg_pps=$(capinfos ${pcap} | grep 'Average packet rate' | awk '{print $4}' | tr -d ',')
tcpreplay-edit --pps=$avg_pps --mtu-trunc -i $iface ${pcap}
After four days, our replay had only gone through about 10-15% of all PCAP files. Given that entire dataset only spans for three days, we were understandably puzzled. Sure, we were aware that replaying with average rate would flatten out all bursts, but that still seemed too much. But we quickly figured out what happened.
That set was written using Moloch/Arkime full packet capture. Like Suricata, it reconstructs sessions from the ground up. All the way to the application layer. And like Suricata, it’s multi-threaded. Flow reconstruction 101 - all packets in a flow need to pass through the same worker. No information exchange happens between workers due to the extreme throughput they need to handle, and each worker can write those packets out to a separate PCAP file. But not all flows are created equal. Some workers will see more traffic volume than others, even if the flow balancer is able to distribute roughly the same number of sessions to each thread. One thread would therefore receive a large HTTP file download while another gets a lot of small DNS queries. The first PCAP file will simply rotate faster.
In other words, our script relied on having sequential PCAP files. But the dataset was not sequential at all. Rather, it consisted of N sequential PCAP subsets, where N corresponds to the number of workers configured in Moloch/Arkime. All in one folder and without worker ID configured as part of the PCAP naming scheme. Not knowing how many workers were used. And we needed to reconstruct it as well as we could, as the dataset was full of sweet simulated attacks, perfect for exercising the algorithmic threat detection we are developing. To put it bluntly, it sucked to be us.
Enter gopacket
As the tcpreplay idea was proposed, I already felt that this approach was not going to be enough. Especially not when we are working with data mining methods where traffic patterns can matter more than actual flow content. Coincidentally, in my previous job I also had to deal with quite large PCAP sets and I built several specialized event pipelines. So, I was already familiar with building custom tools as existing ones simply did not do what I needed. I suppose that comes with being the resident mad scientist. The language I most often chose for the task was Golang (or simply, Go).
To those uninitiated, Go is a statically typed programming language from Google. It boasts a fairly simple C-like syntax, but uses a garbage collector. Code is compiled into a single binary that can be executed on any system with matching target CPU architecture. Programs written in pure Go have no external dependencies, though reliance on some C libraries is quite common. Still, a lot more convenient than intricate dependency chains in most modern applications.
Of course, it can’t compete with C or Rust for raw performance. Those require the user to manage memory, and are thus in an entirely different category. However, Go is built from ground up for simple and thread-safe concurrency, and code is compiled to binary format. Thus, giving a good balance between performance, reliability and development speed. Many companies use Go nowadays for data engineering. In other words, for building middleware processing tools in data pipelines. A glue language between raw source and final application, if you will.
Gopacket is, to put it simply, amazing. It is maintained on Google GitHub organization and, as name implies, provides packet processing capabilities. Decoding packets, reading from and writing to network interfaces, working with PCAP files, etc. Even supporting AF-Packet for efficient packet acquisition! Essentially, it’s like Scapy library in Python, but can actually scale to real traffic volumes.
Having previous experience with gopacket, I instantly had an idea. Why not just build a custom replay tool?
PCAP metadata mapping
Let’s build one then! Might sound like a daunting task, but it’s actually not when cut down to smaller pieces. Firstly, we’d have to discover PCAP beginning and end. Many readers who have worked with post-mortem PCAP sets before might recognize the following command.
tcpdump \
-r /srv/datasets/pub/malware-traffic-analysis/2020-01-10-IcedID-infection-traffic.pcap \
-c1 -n -tttt
The most important parameters are -c1 to only read the first packet from PCAP file and -tttt to format the timestamp in a high-precision human readable format. Extracting that timestamp in a bash script is simply a matter of adding cut, awk, and a few pipes.
But we can build a more powerful version of that with Go. Firstly, we’ll create a special struct for storing those timestamps. As one might guess, a sensible name for this struct is Period. I quite like timestamp handling in the Go standard library. Time type in the time package is not a complex class for storing each timestamp element as a separate value, but simply a wrapper around an int64 numeric. That wrapper provides methods for converting the underlying UNIX epoch (seconds from year 1970) into various timestamp formats, for deriving boolean truth values, for calculating durations, etc. By comparison, I always found the python datetime library to be needlessly overcomplicated for what it actually needs to do.
type Period struct {
Beginning time.Time `json:"beginning"`
End time.Time `json:"end"`
}
For example, calculating the duration for this period is as simple as subtracting the beginning timestamp from end. Resulting Duration is simply another method wrapper for int64.
func (p Period) Duration() time.Duration {
return p.End.Sub(p.Beginning)
}
This period can then be embedded into a custom struct that will hold information about one PCAP file.
type Pcap struct {
Path string `json:"path"`
Root string `json:"root"`
Err error `json:"err"`
Snaplen uint32 `json:"snaplen"`
models.Counters
models.Period
models.Rates
fi os.FileInfo
}
For actually parsing the first PCAP timestamp, we can simply implement a method for our Pcap handler that initializes a new file reader, reads the first packet and updates the Beginning field in our Period struct with timestamp extracted from decoded packet.
func (p *Pcap) ScanPeriod(ctx context.Context) error {
fn := func(r io.Reader) error {
h, err := pcapgo.NewReader(r)
if err != nil {
return err
}
// Get first packet
data, ci, err := h.ReadPacketData()
if err != nil {
return err
}
p.Period.Beginning = ci.Timestamp
Now we can proceed with implementing something more interesting. The method would continue by iterating over all packets and recording the last seen timestamp. Sure, simply seeking to the end of the file handle, but that would complicate compression handling that will be explained a bit later. This loop will take time when dealing with large PCAP files, but at least we can collect more metadata while iterating packets.
That will be useful anyway, as we will need to know the maximum packet size when replaying packets to a real network interface. Incorrect MTU spells a bad day!
for {
data, ci, err = h.ReadPacketData()
if err != nil && err == io.EOF {
break
}
last = ci.Timestamp
size := len(data)
p.Counters.Packets++
p.Counters.Size += size
if size > p.MaxPacketSize {
p.MaxPacketSize = size
}
}
Once the loop encounters the end of the file we can safely update the End field in our Period struct with recorded value. And we’ll also need snapshot length - the amount of data captured from each frame. That information is stored in PCAP metadata and is another piece needed later for when creating a replay writer.
p.Period.End = last
p.Snaplen = h.Snaplen()
The little interface that can
Before moving on to actual replay, let’s have a word or two about IO and data types. The reader may have noticed that the ScanPeriod() method defines an anonymous function that uses io.Reader as only input argument. What’s up with that?
Go is a statically typed language. Meaning that one cannot simply pass arbitrary values and hope to get away with that. For example, attempting to pass numbers to a function written to accept string inputs would result in the program simply not compiling. That’s because every object has a strictly defined data type and attempting to assign incompatible values will be caught on compile rather than runtime. More work from the programmer up front, but many bugs common for dynamic programming languages (e.g., python, javascript, ruby) simply do not exist in this model.
But what if we have multiple vastly different objects that nevertheless behave the same. For example, square and circle objects use different formulas to calculate area, but both calculations result in numeric output value. In our case, we want our PCAP reader to be agnostic to file compression.
Go tackles this problem with interfaces, which is basically a method definition. That definition mandates input and output values, but not the method itself. Any type that implements those methods implicitly also implements the interface. We can then write functions that require or return the abstract interface, rather than any concrete type. Nothing illustrates this better than io.Reader, the little interface that can. Simple in design, yet powerful in the amount of problems it solves.
type Reader interface {
Read(p []byte) (n int, err error)
}
PCAPs can be big. Really big. And offline lab data really does not do anything other than use disk space. So, why not just keep it compressed? Turns out that we can actually do that without losing much functionality. And the io.Reader interface allows us to dynamically handle both compressed and uncompressed files!
Consider the following function. We can peek into the first few bytes of the file to discover the format we’re dealing with. That is known as file magic. We can then open a file handle. If gzip compression is detected, then we pass it to gzip reader instead. Both handlers implement Read() and Close() methods as defined by the io package. So, we can just use io.ReadCloser as a return value. It limits us to only those two operations, but we don’t need anything else anyway.
func Open(path string) (io.ReadCloser, error) {
if path == "" {
return nil, errors.New("Missing file path")
}
m, err := magic(path)
if err != nil {
return nil, err
}
handle, err := os.Open(path)
if err != nil {
return nil, err
}
if m == Gzip {
gzipHandle, err := gzip.NewReader(handle)
if err != nil {
return nil, err
}
return gzipHandle, nil
}
return handle, nil
}
Fun fact about IO handles - they need to be closed. And often programmers forget to do that. So, how about we just build a method that simply takes care of properly opening and closing PCAP file handles. Users can decide what they actually want to do with packets. In just about 8 lines of code (depending on how you count boilerplate). Sounds good?
func (p Pcap) Do(w WorkerFunc) error {
h, err := p.open()
if err != nil {
return err
}
defer h.Close()
return w(h)
}
Functions are first-class citizens in Golang. WorkerFunc is a custom type defined as any function that takes io.Reader as input and returns an error if anything goes wrong. Processing logic is encapsulated inside the function and can be thus defined externally.
type WorkerFunc func(io.Reader) error
The anonymous fn variable in the ScanPeriod method satisfies this definition, allowing us to implement the scanner. Defining a function inside the method has allowed us to update Pcap struct fields from inside the worker. Yet, we are able to re-use the framework later for replay. And it allows us to separate PCAP file handling from packet processing logic, even allowing the former to be imported as a library , not limiting the user to our functionality.
func (p *Pcap) ScanPeriod(ctx context.Context) error {
fn := func(r io.Reader) error {
// Logic goes here
return nil
}
return p.Do(fn)
Concurrency
Wouldn’t it be nice if we could spin up these scanners in parallel. And users could then define the number of concurrent metadata scanners most suitable for CPU core count and IO throughput. This can be achieved by using channels, a Go language primitive for thread-safe communication. Each worker, called goroutine, can push items to or pull from that channel. The channel is basically a FIFO for many to many data sharing. Once a worker has pulled an item from a channel, it’s no longer in there and others cannot access it. Doing that is thread-safe.
Knowing that, let's define a function that takes a list of previously described Pcap structs as inputs. Those objects are still mostly empty. The goal is to implement a concurrency model where N workers scan PCAP files in parallel and users can receive the results asynchronously. The output would therefore be a channel of scanned PCAP handles.
func concurrentScanPeriods(
ctx context.Context,
files []fs.Pcap,
workers int,
) (<-chan fs.Pcap, error) {
// Logic goes here
return tx, nil
}
This model relies on two channels. Firstly, the rx channel is used to distribute tasks for each worker. Secondly, the tx channel is used for emitting results. Neither channel is buffered, meaning that the producer is blocked until the consumer explicitly pulls the item. While we’re at it, we’ll also initialize sync.WaitGroup object to keep track of active workers. We rely on several concurrent functions to make this happen, and each needs to close properly.
var wg sync.WaitGroup
rx := make(chan fs.Pcap, workers)
tx := make(chan fs.Pcap, 0)
We then create individual workers in loop. Note that each iteration increments the waitgroup value whereas workers themselves must decrement it once done. Goroutines are created using the go keyword, and all workers will exit once the rx channel is closed. This event indicates that no more tasks exist. Information about anything that goes wrong during the PCAP file scan is attached to the handler and the user must explicitly check it. Note that error handling can be challenging in concurrent scenarios.
for i := 0; i < workers; i++ {
wg.Add(1)
go func(id int, ctx context.Context) {
defer wg.Done()
logrus.Debugf("Started worker %d", id)
defer logrus.Debugf("Worker %d done", id)
for pcapfile := range rx {
if err := pcapfile.ScanPeriod(context.TODO()); err != nil {
pcapfile.Err = err
}
tx <- pcapfile
}
}(i, context.TODO())
}
Next, we’ll create a feeder goroutine for iterating over unprocessed PCAP files and pushing them to workers. It’s also responsible for properly closing the channel and therefore signaling workers to close.
go func() {
for i, pcapfile := range files {
logrus.Debugf("Feeding %s %d/%d", pcapfile.Path, i, len(files))
rx <- pcapfile
}
close(rx)
}()
Finally, one more goroutine is needed to wait for all workers to finish and close the tx channel. Remember that tx is returned to the user, albeit in read-only mode. According to generally accepted best practice, channel creators are also responsible for closing them. If left open, then calling code would simply deadlock, even if all workers have actually finished.
go func() {
defer close(tx)
wg.Wait()
}()
Metadata JSON
Once the mapping is done, we’re just left with storing the resulting information for use in replay mode. For that, we have defined another struct that stores a list of mapped PCAP files, along with global dataset start and end information.
type Set struct {
models.Period
Files []Pcap `json:"files"`
}
The function that invokes the previously described concurrent scanner for instantiating a new Set object would therefore look like this.
func NewPcapSetFromList(rx []fs.Pcap, workers int) (*Set, error) {
if rx == nil || len(rx) == 0 {
return nil, errors.New("Missing pcap list or empty")
}
ch, err := concurrentScanPeriods(context.TODO(), rx, workers)
if err != nil {
return nil, err
}
s := &Set{Files: make([]Pcap, 0)}
for f := range ch {
f.Calculate()
s.Files = append(s.Files, Pcap{Pcap: f})
}
sort.SliceStable(s.Files, func(i, j int) bool {
return s.Files[i].Beginning.Before(s.Files[j].Beginning)
})
s.Period = calculatePeriod(s.Files)
s.updateDelayValues()
return s, nil
}
The map subcommand would then store the information in a JSON file. Subsequently, replay loads this metadata to avoid re-scanning the entire dataset each time it’s called.
Replay
The replay handle is a construct built around the Set object, with internal fields for maintaining state and exchanging data. Those can include waitgroups, packet channels, error channels, PCAP writer handles, etc. These are omitted from subsequent examples for brevity. Code that instantiates a new Handle would also create all concurrent workers, but won’t activate the replay quite yet.
type Handle struct {
FileSet pcapset.Set
wg *sync.WaitGroup
packets chan []byte
writer *pcap.Handle
// more internal fields
}
func NewHandle(c Config) (*Handle, error) {
if err := c.Validate(); err != nil {
return nil, err
}
h := &Handle{
FileSet: c.Set,
wg: &sync.WaitGroup{},
packets: make(chan []byte, len(c.Set.Files)),
// more internal fields
}
// worker prep code
return h, nil
}
Worker creation follows the same overall principle as described previously. The primary difference being that all PCAP files are replayed at the same time. Each worker will simply sleep for a duration calculated between the global set and individual PCAP start. Workers then produce packets to the packets channel, which is consumed by a single writer. Thus maintaining thread safety on interacting with the network interface. Note that the writer does not exist yet. It will be created later on replay start.
for _, p := range h.FileSet.Files {
h.wg.Add(1)
go replayReadWorker(h.wg, p, h.packets, h.errs, h.speedMod)
}
go func() {
h.wg.Wait()
close(h.packets)
}()
Worker creation code should look familiar already, as it closely mirrors previous scanner initialization. It’s simply written as a separate function, because it involves more code. As this function is fully asynchronous, all data and errors need to be communicated via channels. Also note that function is only allowed to push new data into those channels.
func replayReadWorker(
wg *sync.WaitGroup,
pcapfile pcapset.Pcap,
tx chan<- []byte,
errs chan<- error,
modifier float64,
) {
defer wg.Done()
fn := func(r io.Reader) error {
reader, err := pcapgo.NewReader(r)
// Packet replay code
return nil
}
if err := pcapfile.Do(fn); err != nil && errs != nil {
errs <- err
}
return
After creating the PCAP reader, but before actually reading packets, the worker will sleep. Thus solving our little synchronization problem. We can also set up a numeric modifier for speeding up or slowing down the replay.
if pcapfile.Delay > 0 {
logrus.Infof("file %s start is future, will wait for %s", pcapfile.Path, pcapfile.Delay)
dur := float64(pcapfile.Delay) / modifier
time.Sleep(time.Duration(dur))
}
Just as during the map phase, our gzip-agnostic reader would process PCAP files packet by packet. However, this time we use a timestamp memorized from each item to calculate time delta between two packets. Code can then sleep for that duration before actually pushing the packet to our lone writer. And again, the modifier can speed up or slow down the replay as configured by the user.
for {
data, ci, err := reader.ReadPacketData()
if err != nil && err == io.EOF {
break
} else if err != nil {
return err
}
if ci.Timestamp.After(last) {
dur := float64(ci.Timestamp.Sub(last)) / modifier
time.Sleep(time.Duration(dur))
}
tx <- data
last = ci.Timestamp
}
Diligent readers might have noticed that this concurrency model is little different from metadata scanner. Metadata scanner distributed tasks to N concurrent workers, whereas each worker processed individual tasks fully sequentially. In other words, the distributor, or feeder, fed tasks to an internal channel, whereas workers consumed that channel to pick them up. By comparison, each replay ReadWorker task functions both as worker and feeder. They are all spun up at once, with each performing calculations and packets are then pushed to the central channel to be picked up by a dedicated writer that interacts with the network interface. This approach works as a load balancing mechanism. After all, decompression, packet decode, and timestamp calculations consume the most CPU cycles. However, the effect is almost coincidental to solving the PCAP synchronization problem.
With producers prepared, we are left with only setting up a writer that picks up packets from the central channel and pushes them to the network interface. Yes, that writer could become bottleneck at high packet rates, but packet drift is to be expected. Our goal is to maintain the overall traffic profile, not break theoretical benchmarks. Nevertheless, PCAP submodule in gopacket relies on libpcap and therefore uses Cgo which is usually faster than pure Go implementations.
func (h *Handle) Play(ctx context.Context) error {
if h.writer == nil {
writer, err := pcap.OpenLive(h.iface, 65536, true, pcap.BlockForever)
if err != nil {
return err
}
h.writer = writer
}
defer h.writer.Close()
// set up BPF filters, counters, periodic tickers, etc
loop:
for {
select {
// periodic reporting, error checks, reloads, etc
case packet, ok := <-h.packets:
if !ok {
break loop
}
if err := h.writer.WritePacketData(packet); err != nil {
return err
}
// update counters
}
}
return nil
}
We can then observe the results in terms of event and IDS rule activity in Stamus Security Platform, where the dataset clearly displays day and nighttime traffic patterns. Albeit not corresponding to actual hours when traffic was captured. Our replay is currently configured to loop indefinitely, regardless of time. We simply sleep the replay for four hours between iterations to clearly differentiate iterations.

Figure 1. Kibana events
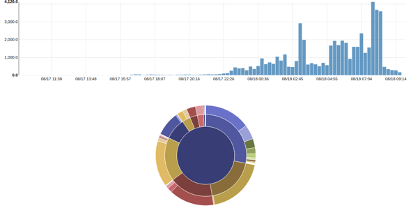
Figure 2. Rules activity
Summary
This blog post is not only a short introduction to GopherCAP, our custom PCAP manipulation tool that we are releasing to the community. It also provides a small glimpse into daily development and QA work needed to build a network security monitoring platform. At the time of this writing, GopherCAP supports:
- Parsing PCAPs for metadata and timestamp extraction
- Replaying those PCAPs to local capture interface while preserving inter-packet timestamps and accounting for delay between each file beginning in asynchronous sets
- Extract files from gzipped tar archives directly to compressed file handles, thus saving space when only a subset of PCAP files are needed from a large archive
Threat hunting is a form of data science. Application development is driven by reliable test cases and user stories, but ours rely on reproducible data to tell that story. Replaying packet capture files with both benign and malicious events is needed to understand and forward these stories. But those files present unique challenges.
Furthermore, our dear MOBsters in NSM communities are well aware that data stored on disk a year ago is not the same today. With each new version of Suricata and Stamus Security Platform, session reconstruction is improved, new network protocols are supported, analytics methods are developed, etc. GopherCap allows us to easily come back to old data to gain new insights.
Try GopherCAP for yourself
GopherCap is available now on the official Stamus Networks GitHub page. We encourage you to give it a try, share your feedback, and even help improve it if you wish. Whereas this post focuses mainly on the initial replay feature, our vision is to - over time - add more PCAP manipulation features and build a unique multitool for the mad scientists in the threat hunting community.
https://github.com/StamusNetworks/gophercap



