Introduction
Elasticsearch and Kibana are wonderful tools but as all tools you need to know their limits. This article will try to explain how you must be careful when reading data and explain how to improve this situation by using an existing Elastisearch feature.
The Problem
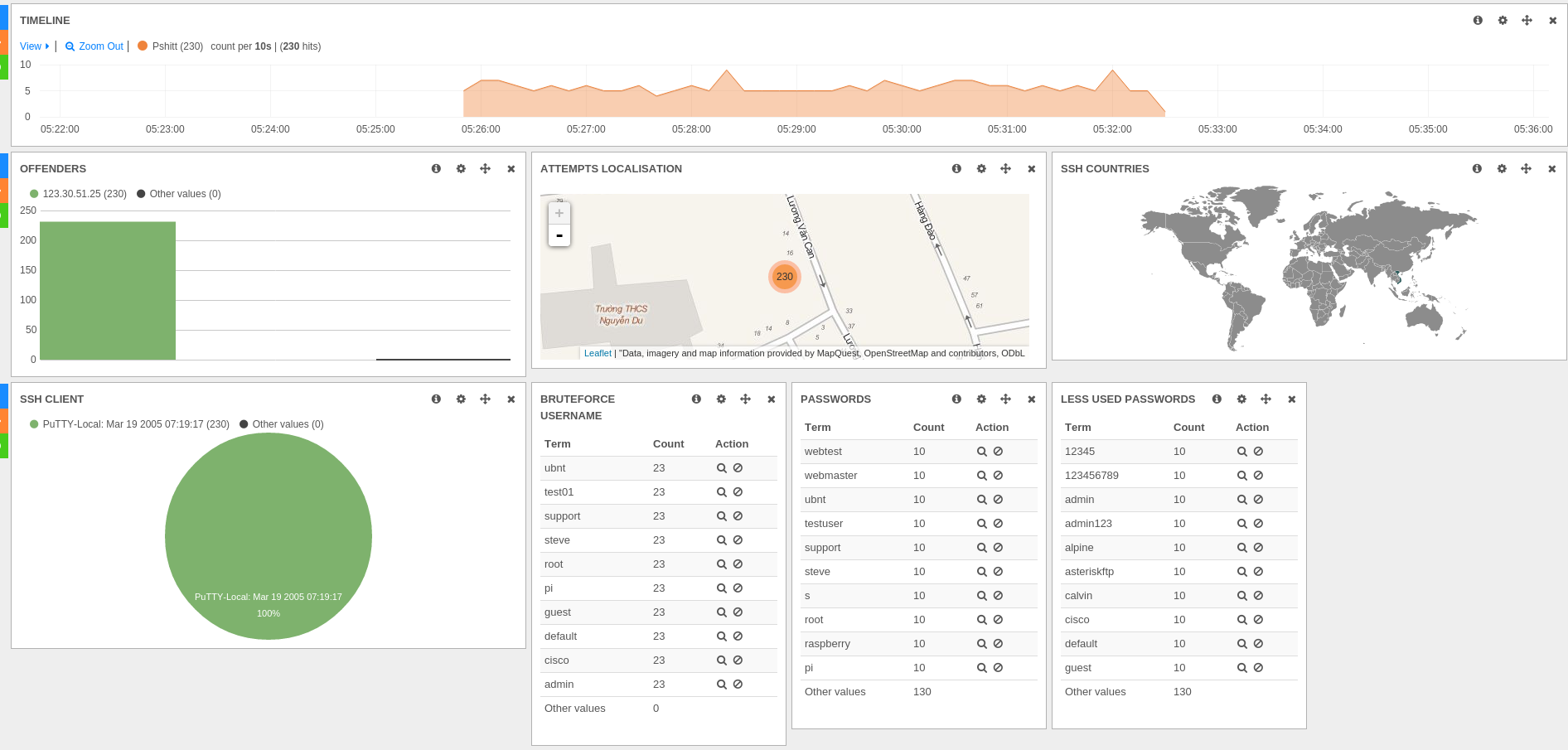
All did start with the analysis of an SSH bruteforce attack coming from Vietnam. This attack was interesting because of the announced SSH client "PuTTY-Local: Mar 19 2005 07:19:17" which really looks like a correct PuTTY software version when most attack don't spoof their software version and reveal what they are using.
The Kibana dashboard was showing all information needed to get a good idea of attacks:
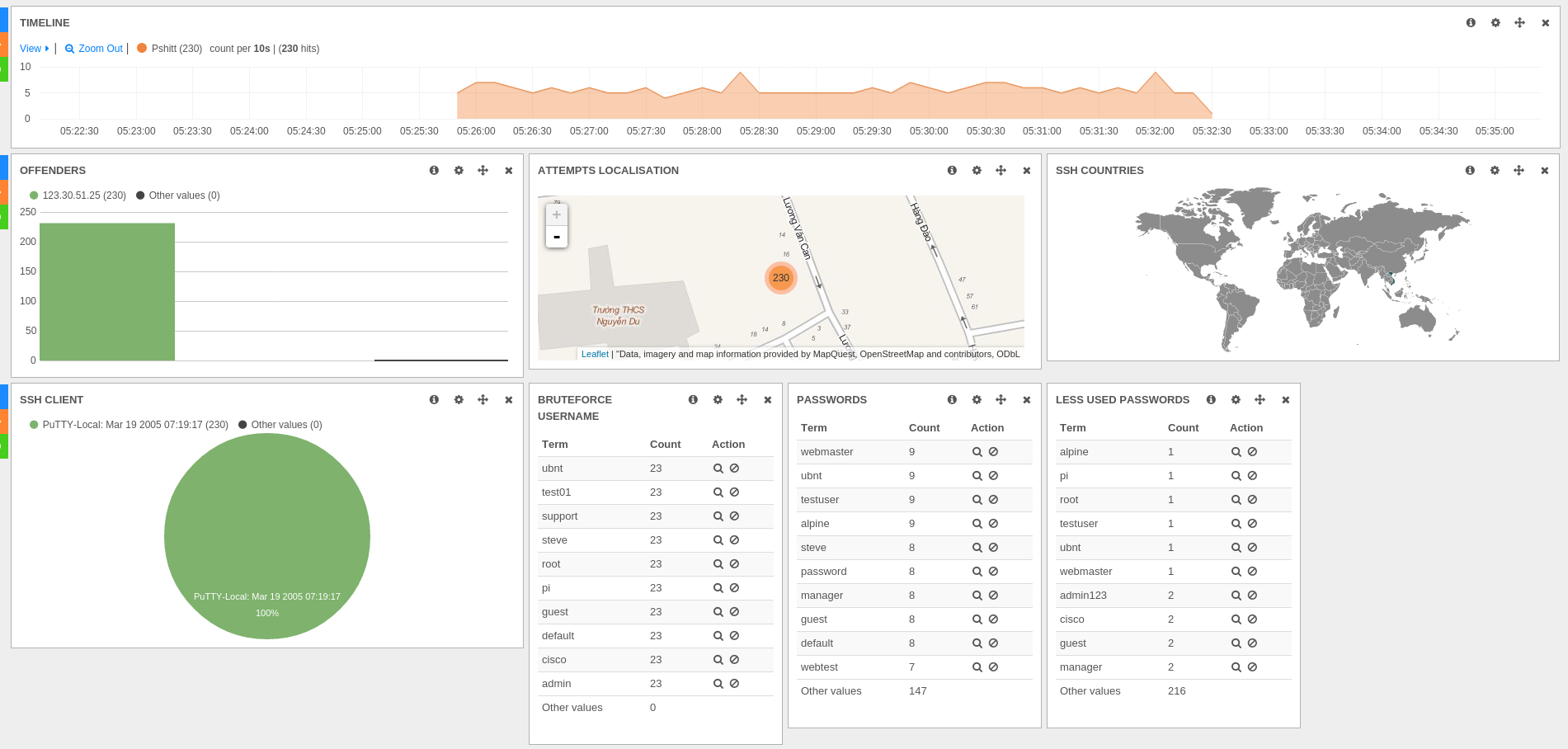
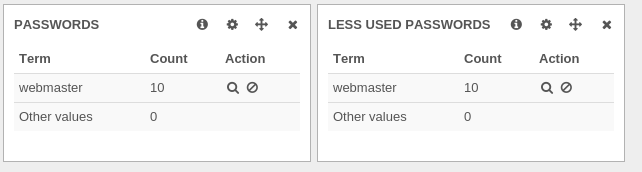
But when looking at less used and most used passwords, there was something really strange:
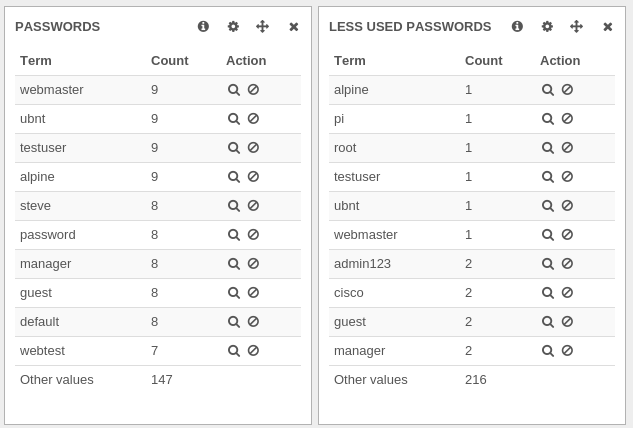
For example, webmaster is seen in the two panels with different values which is not logical.
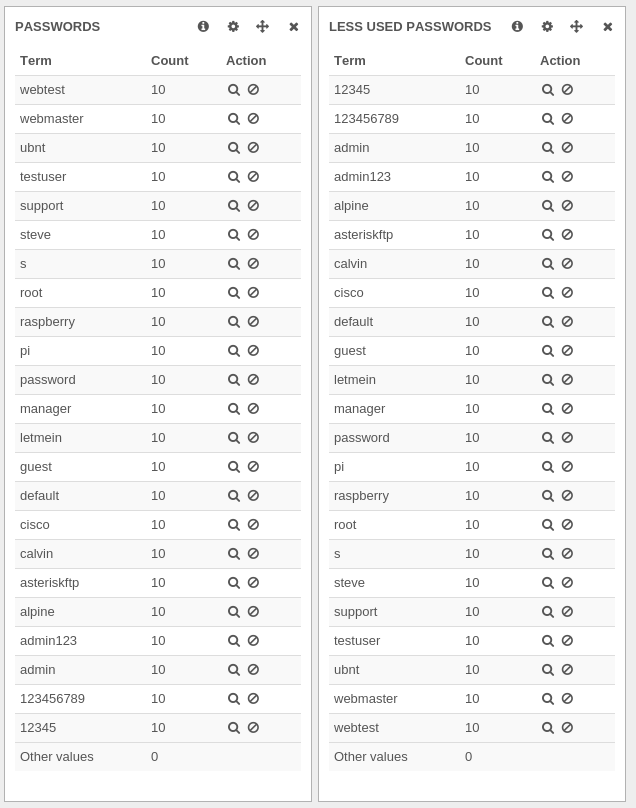
By adding a filter on this value, the result was a bit surprising:
When looking at the detail of events, it was obvious this last result was correct. This SSH bruteforce has tried 10 different logins and has always used the same dictionary of 23 passwords.
To a solution
So the panels with top passwords and less seen passwords are displaying incorrect data in some circumstances. They have been setup in Kibana using the terms type.
This corresponds in Elasticsearch to a facets query. Here's is the content of the query with the filter removed for readability:
{
"facets": {
"terms": {
"terms": {
"field": "password.raw",
"size": 10,
"order": "count",
"exclude": []
},
}
}
So we have a simple request and it is not returning the correct data. The explanation of this problem can be found in Elasticsearch Issue #1305.
Adrien Grand is explaining that a algorithm returning possibly inaccurate values has been chosen to avoid a too memory intensive and network intensive search. The per-default algorithm is mainly wrong when they are more different values than searched values.
We can confirm that behavior in our case by asking for 30 values (on the 23 different passwords we have):
The result is correct this time.
If we continue reading Adrien Grand comment on the issue, we see that a shard_size parameter has been introduced to be able improve the algorithm accuracy.
So we can use this parameters to improve the accuracy of the queries. Patching this in Kibana is trivial:
diff --git a/src/vendor/elasticjs/elastic.js b/src/vendor/elasticjs/elastic.js
index ba9c8ee..8daa72a 100644
--- a/src/vendor/elasticjs/elastic.js
+++ b/src/vendor/elasticjs/elastic.js
@@ -3085,6 +3085,7 @@
}facet[name].terms.size = facetSize;
+ facet[name].terms.shard_size = 10 * facetSize;
return this;
},
Here we just choose a far larger shard_size than the number of elements asked in the query. We could also have used the special value 0 (or Integer.MAX_VALUE) for shard_size to get perfect result. But in our test setup, Elasticsearch is failing to honor the request with this parameter. And furthermore, the result was already correct:
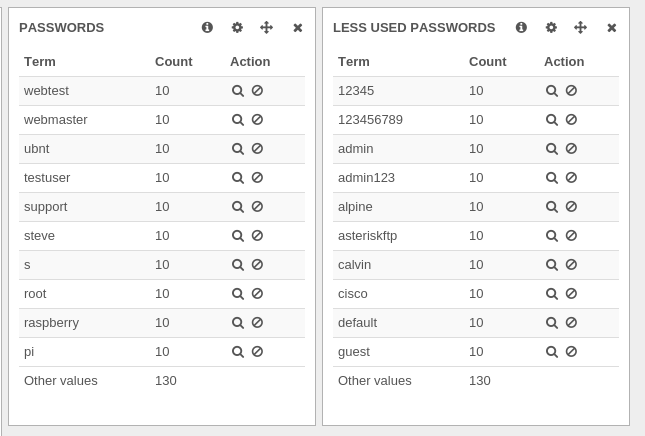
This patch has been proposed to Elasticsearch as PR 2106.
That was a small patch but this fixed our dashboard as the value in the terms panels are now correct: